references/ vs scripts/ (when to use which)
A skill folder can include two optional subfolders: references/ and scripts/. They serve different purposes and choosing the wrong one is a frequent rejection reason. The rule is simple: references/ for static content the LLM reads, scripts/ for executable code the LLM runs. The hard part is recognizing which side of the line your content falls on.
references/: static files the LLM reads on demand
references/ holds files the LLM can READ when it needs them: markdown explanations, JSON lookup tables, sample data, template files, image specifications. The LLM reads these via a file-read tool; it does not execute them.
Typical uses:
- Lookup tables: an array of Israeli area codes mapped to cities, stored as JSON, referenced when the LLM needs to identify a phone number's origin
- Long-form reference content: a 2000-word explanation of the Israeli tax filing process, kept out of SKILL.md (which should stay short and routing-focused) and pulled in only when the LLM hits a specific question
- Templates: sample contracts, sample forms, boilerplate the LLM customizes for the user
- Image specs: prompts for generating illustrations, kept separate from the body
A good references/ entry is something the LLM needs only sometimes, where loading it into context up-front would waste tokens.
scripts/: executable code the LLM CAN run
scripts/ holds code the agent can EXECUTE: validators, parsers, deterministic computations, network calls. The agent invokes scripts via the host's shell tool (Bash in Claude Code, the equivalent in other hosts), reads stdout/stderr, and incorporates the parsed output into its response. There is no built-in "function-call" mechanism for scripts in the Skills spec; scripts are plain executables the agent runs and reads.
Typical uses:
- Deterministic computation the LLM should not redo: a Luhn check-digit algorithm for Israeli IDs (the LLM would re-derive it inconsistently otherwise)
- Parsers: a function that takes a raw Israeli payslip text and returns a structured JSON breakdown
- External lookups requiring an API key: a function that calls a government API to look up business registration info
- Network calls: scraping a public table, hitting an RSS feed
Scripts must be self-contained (declare all dependencies in the script header), include a clear usage comment at the top, and write to stdout in a predictable format the LLM can parse.
The decision tree
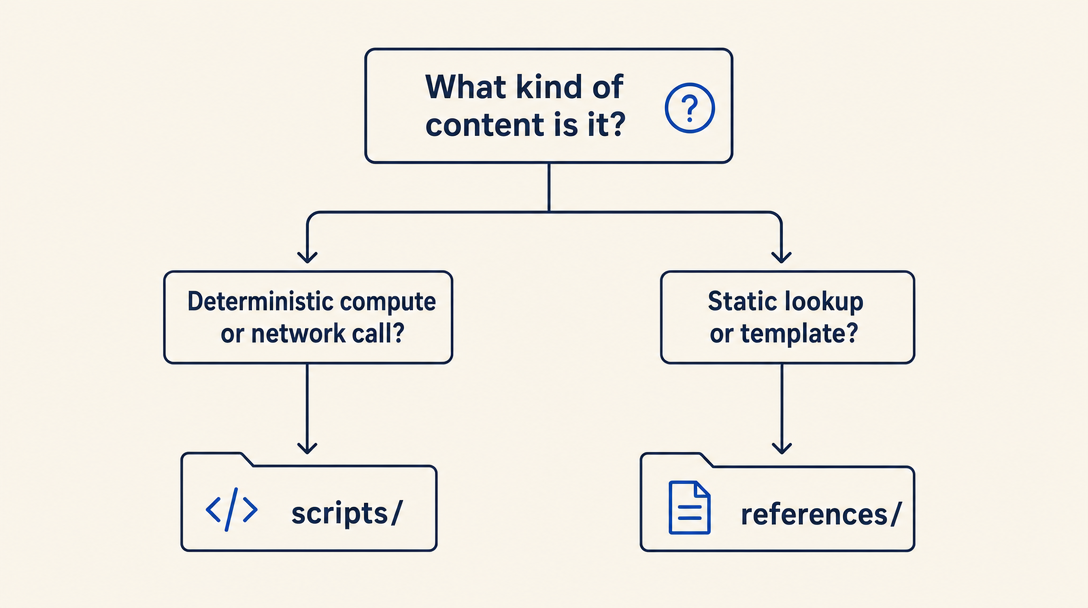
When you have content that supports your skill, ask:
- Is it deterministic computation the LLM might re-derive wrong? →
scripts/ - Does it require an API key, network call, or filesystem write? →
scripts/ - Is it a static lookup, template, or long-form explanation the LLM needs only sometimes? →
references/ - Is it a brief, always-relevant rule or example? → Inline in
SKILL.mdbody - Is it a long, always-relevant rule the LLM must always know? → Probably should not be in a skill; consider a system prompt or a different skill that covers it
File size and structure
Keep references/ files under 5000 words each (~20KB). If you need more, split into multiple files and let the LLM pick the right one. scripts/ files should be self-contained: a single script under ~200 lines is easy to maintain; anything larger should probably be split or become a real package.
Avoid:
- Pasting a 50-row lookup table into the SKILL.md body. Move it to
references/<table-name>.jsonand reference it from the body ("see references/area-codes.json"). - Writing a Python script inside SKILL.md's body as a code fence. Move it to
scripts/<name>.pyand reference it. - Putting binary files (PNG, ZIP) in
references/unless they are sample data the LLM specifically inspects. Catalog images live in the website monorepo, not the skill folder.
Study example: israeli-id-validator's scripts/
The israeli-id-validator skill (npx skills-il add developer-tools/israeli-id-validator) ships a small TypeScript file in scripts/ that implements the Luhn check-digit algorithm for Israeli national IDs. The body of SKILL.md describes when to use the algorithm; the actual deterministic math lives in the script. That is the textbook example of "deterministic compute belongs in scripts/."
For a contrasting example, install israeli-phone-formatter (npx skills-il add developer-tools/israeli-phone-formatter) and study how it uses references/ to store the lookup table of Israeli prefixes (mobile, landline, special-service) without inlining them into the body.
The most common mistake in Chapter 4: pasting a long lookup table into the SKILL.md body instead of references/. Symptom: the body is 80 percent table and 20 percent actual decision rules. Fix: move the table to a JSON file in references/ and reference it from the body. Token efficiency improves, and the body becomes readable as decision logic again.
Want to keep reading?
Sign in to unlock the rest of the course and track your progress.