האנטומיה של SKILL.md
SKILL.md טוב עושה שלושה דברים בו זמנית: אומר ל־LLM מתי לטעון את עצמו (התיאור), מלמד את ה־LLM איך לבצע את המשימה (הגוף), ונותן ל־LLM מספיק דוגמאות כדי להתמודד עם edge cases בלי להעביר את זה למשתמש. אם אחד מהשלושה חסר, הסקיל או שלא נטען (כשל בתיאור), או שעושה את הדבר הלא נכון (כשל בגוף), או ששואל את המשתמש יותר מדי שאלות מבהירות (כשל בדוגמאות).
שדות ה־frontmatter
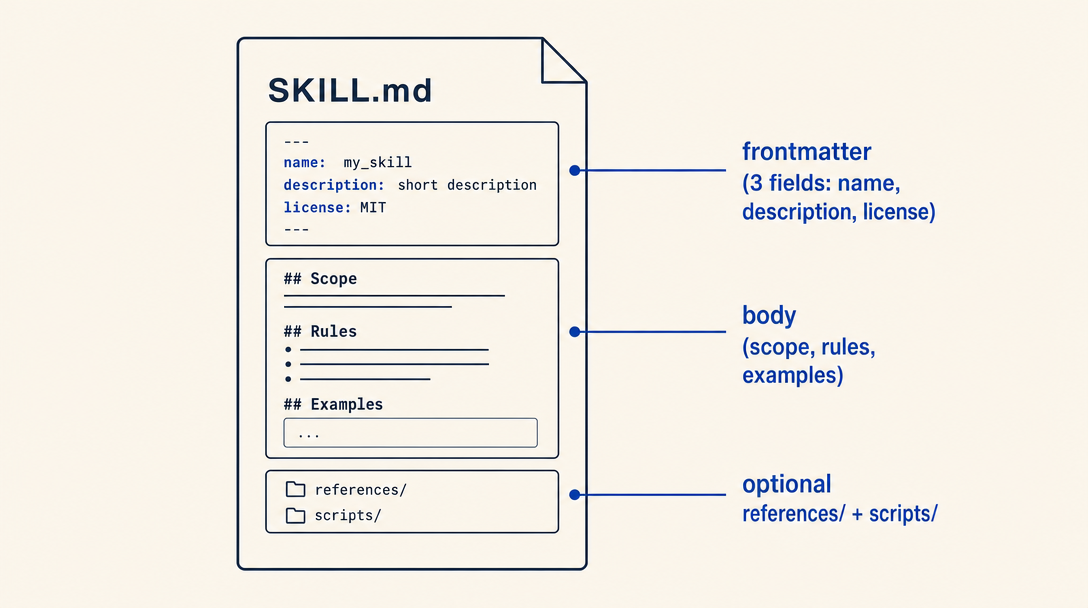
---
name: israeli-id-validator
description: Validate Israeli national ID numbers (תעודת זהות) using the Luhn-style check-digit algorithm. Use when a user pastes a 9-digit ID and asks "is this valid", or when generating sample IDs for testing. Do NOT use for foreign passport numbers or business registration numbers.
license: MIT
---
nameחייב להיות ב־kebab-case, חייב להיות זהה לשם התיקייה בדיוק, וזה ה־slug שה־LLM משתמש בו פנימית כדי לזהות את הסקיל. בחרו משהו ספציפי:israeli-id-validator, לאid-tools. דרישה של המפרט.descriptionהוא השדה הכי חשוב בסקיל. בסביבות הרצה שמשתמשות בניתוב לפי תיאור (skill discovery של Claude Code זאת הדוגמה הקנונית), ה־LLM קורא בעיקר את השדה הזה כדי להחליט אם לטעון את הסקיל לקונטקסט. בסביבות אחרות המשתמש בוחר את הסקיל מרשימה ידנית, אבל התיאור עדיין הדבר הראשון שה־LLM רואה. תתייחסו אליו גם כקופי שיווקי וגם כמפרט ניתוב. דרישה של המפרט.licenseבדרך כללMIT. המפרט המקורי של Anthropic מתייחס ל־license כהמלצה ולא כדרישה קשיחה, אבל קטלוג skills-il ורוב הכלים באקוסיסטם מצפים שהוא יהיה שם. כללו אותו.
התיאור הוא קלט הניתוב
בסביבות שמגלות סקילים אוטומטית לפי תיאור (Claude Code זאת הדוגמה הקנונית), ה־LLM סורק את התיאורים של הסקילים הזמינים כדי להחליט איזה (אם בכלל) לטעון. הוא לא קורא את הגוף. הוא לא קורא את references/. הוא קורא רק את התיאור. בסביבות שבהן המשתמש בוחר סקיל ידנית מרשימה (Claude Desktop, חלק מהזרימות של Cursor), התיאור הוא עדיין הסיכום שמופיע למשתמש ושקובע אם הוא יקליק. כך או כך, התיאור צריך:
- לתת שם ברור למשימה (בשתי השפות של המונח, אם יש שם בקונטקסט ישראלי)
- להפעיל על דפוסי שפה טבעית שמשתמש באמת היה משתמש בהם
- לפסול מקרים שנראים דומים אבל דורשים סקיל אחר
הדפוסים "Use when..." ו־"Do NOT use for..." הופכים את זה לקונקרטי:
"Validate Israeli national ID numbers (תעודת זהות) using the Luhn-style check-digit algorithm. Use when a user pastes a 9-digit ID and asks 'is this valid', or when generating sample IDs for testing. Do NOT use for foreign passport numbers or business registration numbers."
הסעיף "Do NOT" קריטי. בלעדיו ה־LLM עלול לטעון את הסקיל הזה כשהמשתמש שואל על דרכון רומני, ואז ינסה להפעיל את אלגוריתם ספרת הביקורת הישראלית וייכשל בצורה מבלבלת. עם הסעיף "Do NOT", ה־LLM מנתב נכון למקום אחר.
מבנה הגוף: scope, חוקים, דוגמאות, אנטי־דפוסים
הגוף הוא מה שה־LLM קורא אחרי שהחליט לטעון את הסקיל. הוא צריך ארבעה חלקים, פחות או יותר בסדר הזה:
- Scope (פסקה אחת): מה בדיוק הסקיל הזה מכסה, מנוסח בצורה יותר מדויקת ממה שהתיאור איפשר.
- חוקי החלטה (הבשר של הסקיל): הלוגיקה אם־אז שה־LLM צריך להפעיל. השתמשו ברשימות, עצי החלטה, או דוגמאות עבודה. תימנעו מפרוזה.
- דוגמאות עבודה (חובה): תראו את הקלט, את החשיבה, ואת הפלט. כסו את המקרה הטיפוסי ולפחות edge case אחד. בלי דוגמאות עבודה ה־LLM ימציא את התנהגות הגבול.
- אנטי־דפוסים (מומלץ): תגידו ל־LLM מה לא לעשות, גם אם זה נשמע מפתה. אנטי־דפוסים מונעים מצבי כשל שאחרת היו נראים נכון.
דוגמה ללימוד: israeli-id-validator
התקינו את מאמת תעודת זהות (israeli-id-validator) דרך npx skills-il add developer-tools/israeli-id-validator וקראו את SKILL.md. זה סקיל קטן וממוקד (~150 שורות) עם scope ברור, אלגוריתם דטרמיניסטי ב־scripts/, ודוגמאות עבודה קונקרטיות. זה הרפרנס הכי נקי ל"איך סקיל ראשון קטן צריך להיראות".
הטעות הכי נפוצה בפרק 2: כתיבת תיאור עמום מדי. "סקיל לדברים ישראליים" נטען בכל שיחה בקונטקסט ישראלי ולא עושה כלום שימושי באף אחת מהן. תבחרו משימה אחת. תנו לה שם ספציפי. הוסיפו את הדפוסים "Use when..." ו־"Do NOT use for...".
רוצים להמשיך לקרוא?
התחברו כדי לפתוח את שאר הקורס ולעקוב אחרי ההתקדמות שלכם.